
Did you hear about continues integration and continues delivery? I hope you did. If you work in a company which has more than 20 software engineers - you should at least hear about those - if not, mhm I’m really excited to say something about that to you :) So - what are CI/CD and how make those in a right way? I’m going to describe both technics a little bit, and also I’m going to point out some annoying behaviour I often observe.
Both technics - as their name suggest - are about doing something continuously. What is most frequently act according to the software development process? … building and testing. You want to be sure if your changes do not break something, aren’t you?
Moreover, it would be nice if these changes can be deployed. What if we work with 4 or 5 other engineers and you really have no time and no desire to look at someone local environment every time you would ensure that everything works okay? We should delegate building&testing to some centralised remote place where each team member can run and check his changes - and that’s called: Continues Integration. Every time you make even little change and push it to the repository, our set of predefined actions is running. When the pipeline is complete, you should see success or failure. Success means - that version of our application is running correctly, so we can deploy it to some environment. Why do not deploy it just right now? Such deployment calls Continues Delivery - a situation when we can deliver a version of the application continuously.
To make describing the problem a little bit easier, let assume we have a team. Our team members are Bob, Fred, John and Matt. These guys have an excellent job to do - they need to create an online bookstore. Bob starts first, so he creates a project structure with initial libraries set, and other startup stuff, rest of team members are getting his changes and start working on their features. After one week the whole team decided to push and merge their changes to the main branch ![]() - Bob goes first and after his merge … everyone got conflicts, Fred tries to resolve conflicts, and he needs to ask other guys about what he should drop or keep - after some time Fred resolve all conflicts at his branch. John does pretty the same stuff and after that Matt would like to get knowledge if everything is okay so there is an idea to deploy an application to some server. Unfortunately is not … he recognises that some library which was added in the middle of a week caused a critical problem. They have no choice - they need to drop it. All features which our team made already uses that library, so the whole team need to implement the same but in a different way. The workweek is lost.
- Bob goes first and after his merge … everyone got conflicts, Fred tries to resolve conflicts, and he needs to ask other guys about what he should drop or keep - after some time Fred resolve all conflicts at his branch. John does pretty the same stuff and after that Matt would like to get knowledge if everything is okay so there is an idea to deploy an application to some server. Unfortunately is not … he recognises that some library which was added in the middle of a week caused a critical problem. They have no choice - they need to drop it. All features which our team made already uses that library, so the whole team need to implement the same but in a different way. The workweek is lost.
The world would look like that without CI&CD technics. So how may we never make that happens?
Continuous Integration
It allows us to check our changes(commits) against a set of operations we defined. That set of operations calls: the pipeline. A pipeline may have few sub-sets of operations - those sub-groups usually calls stages. For example build stage, test stage, deploy stage. We can also create different pipelines based at the branch name. For example, you may wish to run e2e tests only for release candidates branches. Few of the most popular CI providers are:
-
Gitlab CI (gitlab) - free for every gitlab user, a pipeline configuration is inside single
.gitlab-ci.ymlfile. -
Travis (GitHub) - free only for open-source projects, a pipeline configuration is inside single
.travis.ymlfile. - Jenkins (any repo) - self-hosted, you can do everything with the help of Jenkins, but it is a little bit harder to configure than others solutions.
A simple example of pipeline configuration (.gitlab-ci.yml):
image: java:8
stages:
- build
- deploy
build_app:
stage: build
script: ./gradlew build
artifacts:
paths:
- build/libs/demo-0.0.1-SNAPSHOT.jar
deploy_app_to_cloud:
stage: deploy
script:
- curl --location "https://cli.run.pivotal.io/stable?release=linux64-binary&source=github" | tar zx
- ./cf login -u $CF_USERNAME -p $CF_PASSWORD -a api.run.pivotal.io
- ./cf push
only:
- masterThe CI process is hardly connected to a repository so let’s say something about the repository workflow. You probably use “feature branch” most common, aren’t you?
The basic flow may look like:
- You have XXX repository with a master branch
- You check out a master branch and create the new feature/YYY branch
- After some time when you have finished your work, you are going to create a PULL/MERGE request from your feature/YYY to the master branch
The most important rule here and maybe the most important thing I would say in that post is:
Git feature branches are not pickled cucumbers!
So please please please don’t do that:

I see behaviour like this one regularly and sometimes it is tough to convince someone to not doing that. Publish work progress in smaller parts is always the better choice even for your teammates - what would you preferer to review, 10 or 50 files with changes? :) The continues integration and the continues delivery needs fast and quick development process by the foundation. To do so, every developer in a team should keep their own features maximum 1-day life-long. Why?
Because then and only then a team can quickly respond if things start moving in the wrong direction. On the other hand, if you keep your feature branches as small as possible, you probably never be pushed to resolve some harrowing conflicts - trust me. To sum up - If you are wondering: Should I split THAT ticket/issue into the smaller tickets or no? The answer almost always is - YES, you should.
Continues Delivery
Okay, let’s say something about the CD process. It is not used so common as CI, but it should be. This process is all about deployed specified version of an application automatically - it may use artefacts from the CI pipeline, but it is not steel rule.
In short:
- application is built correctly (all previous pipeline steps are green)
- deploy step is coming in, and it may be something like sending some artefact to the server or just triggering some appropriate webhook which download specified version of the application and deploy it under the hood
Usually, you would not want to publish your recent version directly to the production, would you? The underlying case is to have few deploy environments, one for development process other for acceptance tests etc. I made the following diagram which should explain the concept.
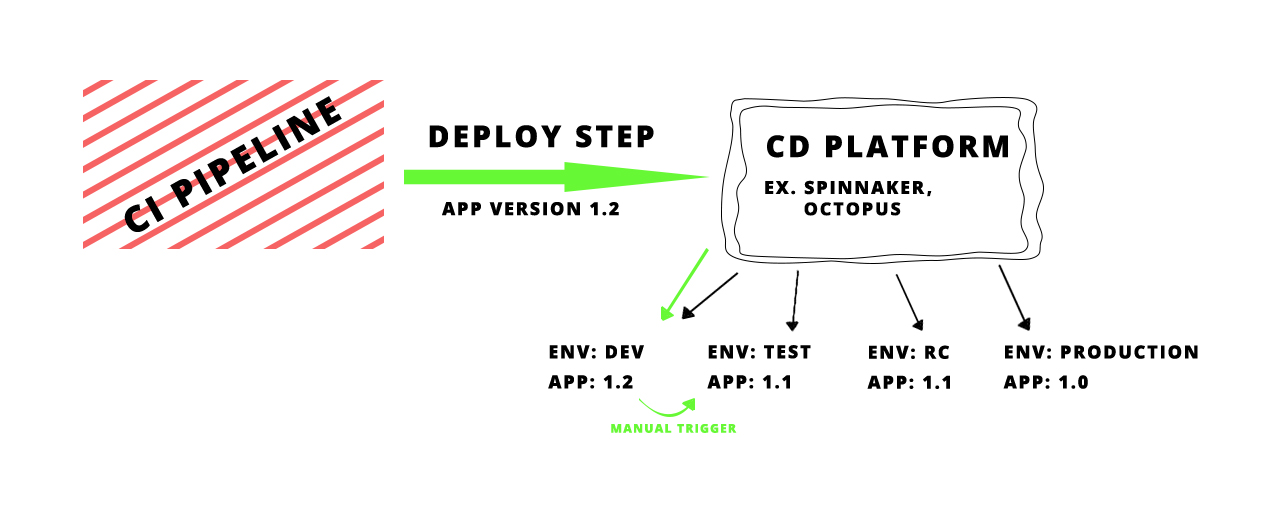
Team workflow
There are a lot of available git ci/cd workflows described on the internet but to sum up today post, I would like to share my favourite one with you. Let have a look:
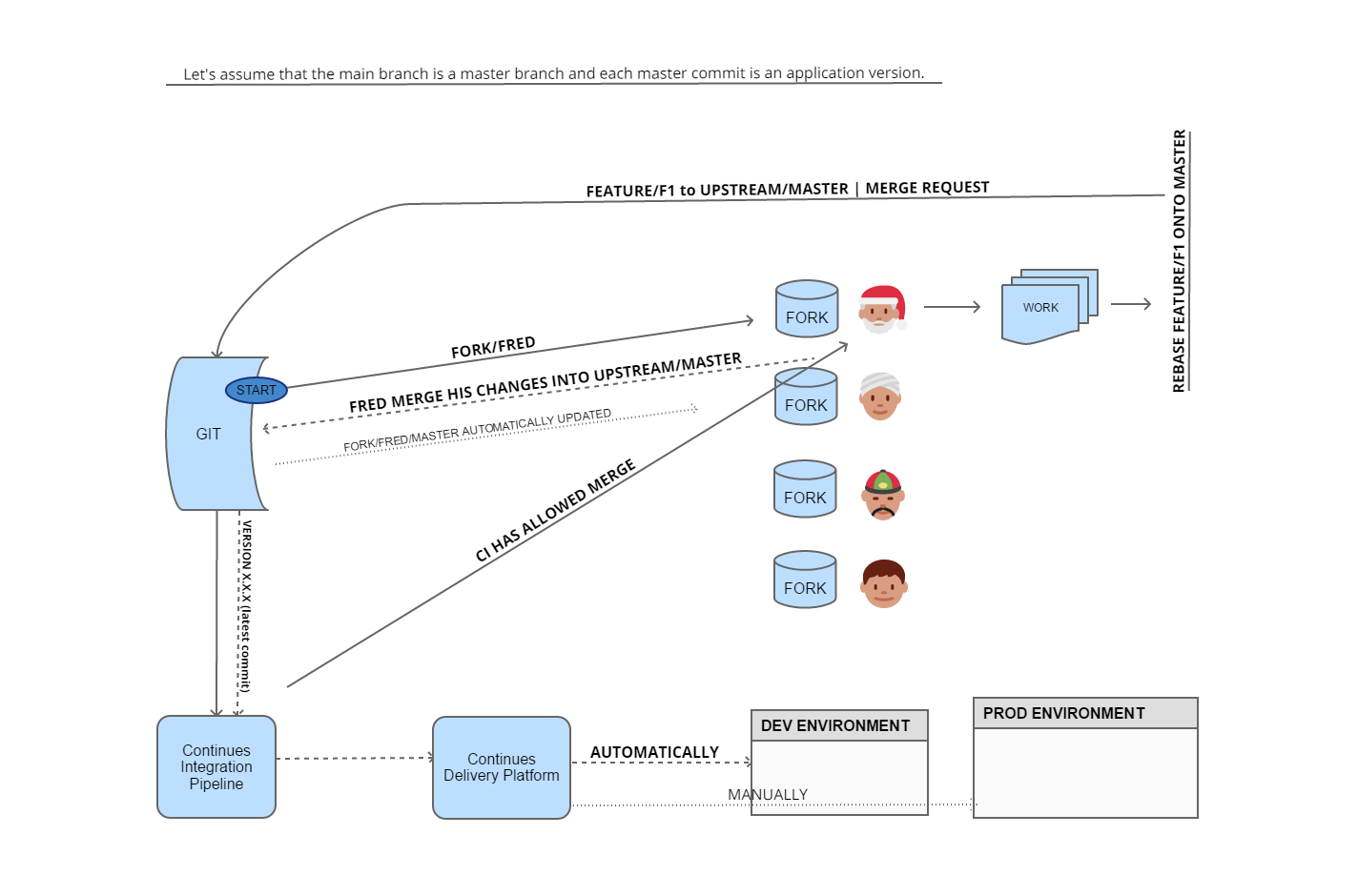
What happens here?
1. Every team member has its fork of the central repository (fork/fred, fork/bob etc.)
2. Each local fork has configured master/develop whatever it name is as a mirror from upstream to keep it always updated with the mainstream version
3. Fred has some feature (max 1 day lifelong) completed after some time. He rebase his feature onto the master branch and then creates appropriate merge request to the UPSTREAM/MASTER (not fork). Git flow may look like:
$ git checkout master
$ git pull
$ git checkout feature/F1
$ git rebase master
$ git push4. After successfully pipeline Fred merge his feature.
5. The latest commit from the upstream/master triggers a new pipeline with additional deploy step
6. After some time our team have the latest version available in a dev environment
7. Each time when team decide to move DEV app version to the next stage someone needs to push DEV deployed version to the next environment, for example, production. Of course, each environment may be different in terms of configuration (database connection, external API tokens etc) and other runtime provided kind of stuff.